

Table of Contents
What is Kubernetes?
Kubernetes natively provides the possibility to span separate physical locations—also known as data centers, failure zones, or more frequently availability zones—connected via redundant, low-latency, private network connectivity.
Kubernetes Architecture for PostgreSQL
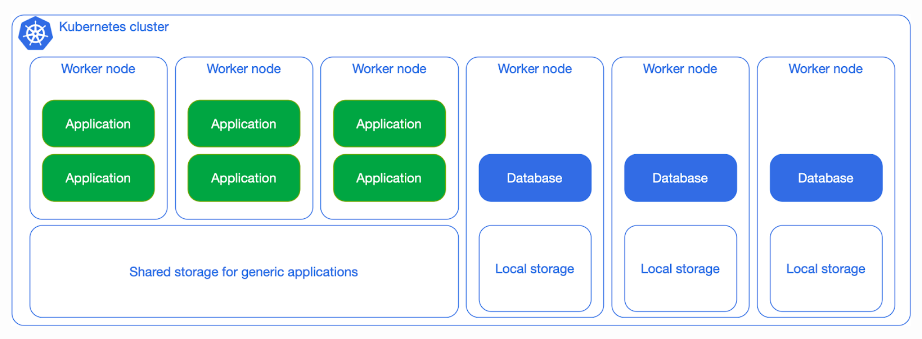
Dedicated workloads, local storage
Let’s say you have a huge, important database that you want to give extra attention to. You can dedicate a single worker node to it, as shown in the diagram below:
Multi-availability Zone Kubernetes Clusters
The minimum recommended number of availability zones for a Kubernetes cluster is three (3), to make the control plane resilient to the failure of a single zone. This implies that all data centers are always operational and capable of handling multiple workloads at once.
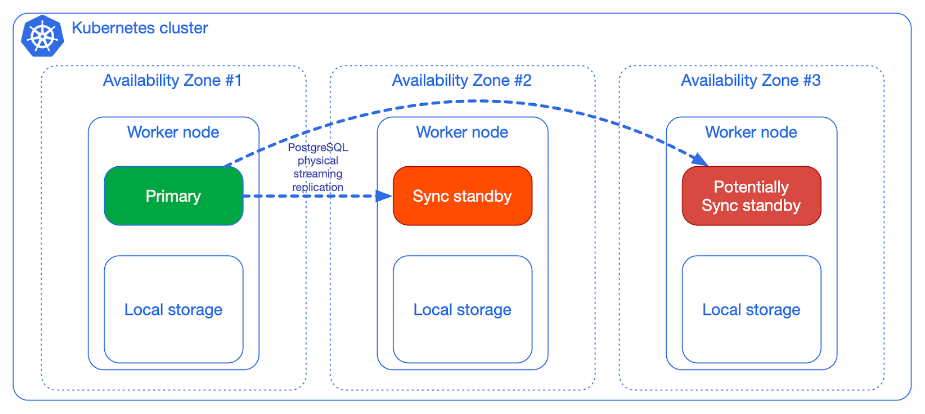
This scenario is recommended for PostgreSQL usage. It is the perfect example of merging the two worlds: This architecture enables the CloudNativePG operator to have full control. This includes, among other operations, scheduling the workloads in a declarative manner, automated failover, self-healing, and updates. Each will operate smoothly among all zones on a single Kubernetes cluster.
In distributed database management systems, this architecture is also known as the shared-nothing architecture.
The dedicated worker node per Postgres instance in 3 different availability zones, with at least a synchronous replica, in a single Kubernetes cluster is without any doubt the best experience of running Postgres.
Also Read: What is cloud native-PG?
Beyond the Single Kubernetes Cluster
The same architecture you adopted in a single Kubernetes cluster can be replicated in one or more regions. A PostgreSQL cluster with a primary and two standby servers (one synchronous) is shown on the left side of the picture below. Continuous backup is in place, with the primary archiving WAL files at least once every 5 minutes in an object stored in the same region of the cluster, and physical base backups being stored irregularly (once a day or a week, depending on your requirements). The object store could be either in the public cloud or internal to the cluster—to be relayed to a public cloud service or a remote location using the selected object store capabilities for long-term retention.
As you can see, the architecture is symmetrical with a designated primary from which the local replicas are kept in synchronization through native streaming replication; a designated primary is a standby that is ready to become primary in case of failure of the primary region. This shows that a regional object store has been configured to handle basic backups and WAL files, which are continuous backups.
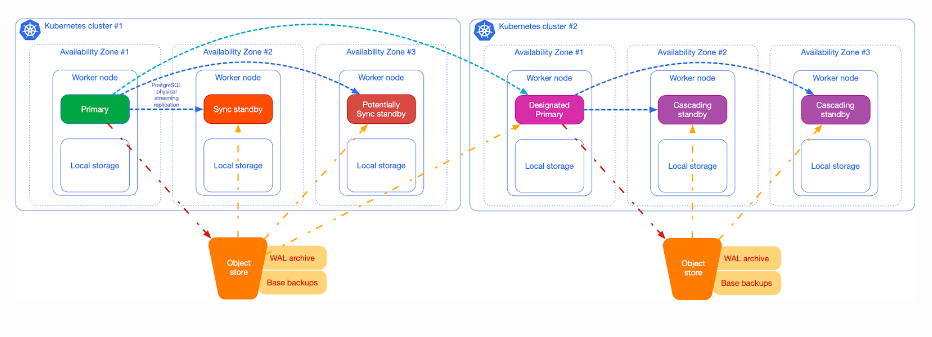
Just by relying on Postgres replication, you can easily have backup objects in two regions.
You can add more replica clusters in cascading replication if you need to. The following sketch highlights an example of a Postgres cluster replicated in three regions (for example, America, Europe, and Asia Pacific).
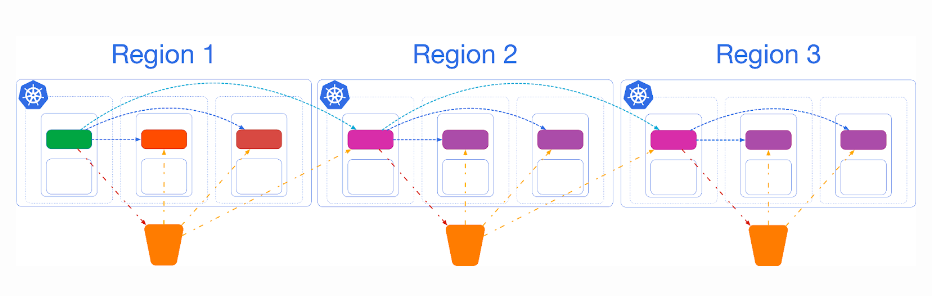
As mentioned at the start, replica clusters are the only option with a low RTO that can save you from data center failures in the case of a single availability zone Kubernetes cluster.
Single-availability Zone Kubernetes Clusters
Even if your K8s cluster has only one availability zone, CloudNativePG still provides you with an extensive list of features to improve DR and HR results for your PostgreSQL databases, pushing the single point of failure (SPoF) to the level of the zone as much as possible.
This situation is common for self-managed Kubernetes clusters running on-premises where only one data center is available.
Having only two availability zones precludes users from creating a multi-availability zone Kubernetes cluster and forces them to create two different Kubernetes clusters in an active/passive configuration, where the second Kubernetes cluster is used primarily for disaster recovery.

It becomes even more crucial for HA in this situation that the PostgreSQL instances are located on separate worker nodes and do not share storage.
For DR, you can push the SPoF above the single zone by using one more cluster to host “passive” PostgreSQL replica clusters. As with other Kubernetes workloads in this scenario, promoting a Kubernetes cluster as primary must be done manually.
Deployments across Kubernetes Clusters
CloudNativePG supports deploying PostgreSQL databases across multiple Kubernetes clusters through a feature called Replica Cluster.
The diagram below depicts a PostgreSQL cluster spanning over two Kubernetes clusters, where the primary cluster is in the first Kubernetes cluster and the replica cluster is in the second. The second Kubernetes cluster acts as the company’s disaster recovery cluster, ready to be activated in case of disaster and the unavailability of the first one.
A replica cluster can have the same architecture as the primary cluster. In place of the primary instance, a replica cluster has a designated primary instance, a standby server with an arbitrary number of cascading standby servers in streaming replication (symmetric architecture).
The designated primary cluster can be promoted at any time, making the replica cluster a primary cluster capable of accepting write connections.
CloudNativePG does not perform any cross-cluster switchovers or failovers at the moment. Such operations must be performed manually or delegated to a multi-cluster or federated cluster-aware authority.
CloudNativePG allows you to define multiple replica clusters. You can also define replica clusters with a lower number of replicas and then increase this replica when the cluster is promoted to primary.
Docker vs Kubernetes
Docker and Kubernetes are both popular technologies in containerization and container orchestration spaces, but they serve different purposes and are often used together.
Docker: Manages containerization (creating, running, and packaging applications in containers).
Kubernetes: Kubernetes orchestrates and automates containerized applications’ deployment, scaling, and management. It works with containers created by Docker and other container runtimes.
Also Read: Deploy Cloud Native PostgreSQL on Kubernetes



Be the first to comment